Statistical Machine Learning
Machine learning algorithms build a mathematical model of sample data, known as “training data”, in order to make predictions or decisions without being explicitly programmed to perform the task
- Supervised learning - Trained on data that contains both the inputs and the desired outputs. Supervised learning algorithms include classification and regression.
- Unsupervised learning -Unsupervised learning algorithms take a set of data that contains only inputs, and find structure in the data
Linear regression
This is used for linear modelling of continuous outputs
Where $\mathrm { w } ^ { T } \mathrm { x }$ is the scalar product of input x and models weights W. $\epsilon$ is the residual error between the predictions and the true value.
Maximum likelihood estimation (least squares)
Assuming that the training examples are independent and identically distributed(iid)
we can equivalently minimize the negative log likelihood
Here MLE is the one that reduces the sum of squared errors
Where RSS is residual sum of squares
Gradient of this is given by
Equating to zero we get
Bayesian linear regression
Sometimes we want to compute the full posterior over w and $\sigma^2$. If we assume Gaussian prior and that the X is distributed in Gaussian then;
If $\mathbf { w } _ { 0 } = 0 \text { and } \mathbf { V } _ { 0 } = \tau ^ { 2 } \mathbf { I }$ then the posterior mean reduces to ridge regression estimate.
Logistic regression
Logistic regression corresponds to the following binary classification model
The negative log-likelihood for logistic regression is given by
This is also called cross entropy error function.
The gradient is given by
We can use gradient descent to find the parameters
Bayesian logistic regression
If we assume a Gaussian Prior along with the Bernoulli likelihood
$p ( \theta ) = \frac { 1 } { \sqrt { 2 \pi \sigma ^ { 2 } } } \exp \left( - \frac { 1 } { 2 \sigma ^ { 2 } } ( \theta - \mu ) ^ { \prime } ( \theta - \mu ) \right)$
| The posterior is given by $P ( \theta | D ) = \frac { P ( y | x , \theta ) P ( \theta ) } { P ( y | x ) }$ |
| Where $P ( y | x ) = \int P ( y | x , \theta ) P ( \theta ) d \theta$. |
This is typically intractable for most problems. We also want to predict y given a new x and the current data
We can drop D as $\theta$ summarizes it.
Using Monte carlo estimates

Support Vector Machines
The goal of support vector machines is to find the hyperplane that separates the classes with the highest margin. The points that define the margin are called support vectors.
The Function is the signed distance of the new input x to the hyperplane w
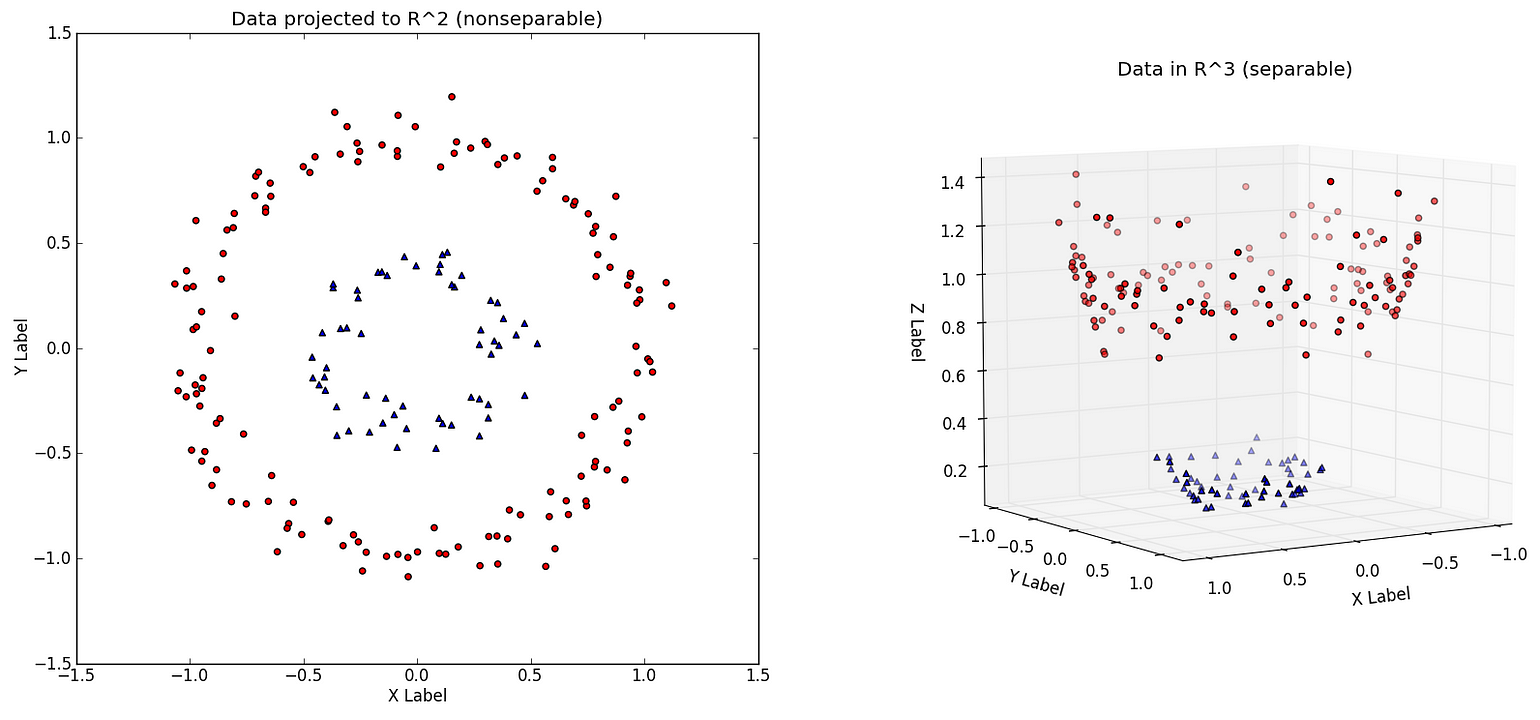
If the classes are not linearly separable then we can use kernels to linearly classify in higher dimensions.
We minimize
Types of Kernels
- Linear $K \left( x , x _ { i } \right) = \sum \left( x \times x _ { i } \right)$
- Polynomial $K \left( x , x _ { i } \right) = 1 + \sum \left( x \times x _ { i } \right) ^ { d }$
- Radial Basis $K \left( x , x _ { i } \right) = e ^ { - \gamma \sum \left( \left( x - x _ { i } \right) ^ { 2 } \right) }$$

Naive Bayes
The Naive Bayes is a classifier assumes that the features of each data point are all independent. It is widely used for text classification.
k-nearest neighbors(KNN)
KNN is a non-parametric approach where the response of a data point is determined by the nature of its k neighbors from the training set. It can be used in both classification and regression settings.
Some of the commonly used distance metrics are:
- Euclidean $d ( a , b ) = \sqrt { \sum _ { i = 1 } ^ { n } \left( a _ { i } - b _ { i } \right) ^ { 2 } }$
-
Manhattan $d ( a , b ) = \sum _ { i = 1 } ^ { n } \left a _ { i } - b _ { i } \right $
Tree-based and ensemble methods
Decision Tree
We recursively split the input space based on a cost Function For Continuous output we use Sun of squared error
For Discrete output we use Gini Index which is a measure of statistical purity of a classes

Random Forest
Random forest is an ensemble technique which uses bagging and decision trees. We create multiple deep trees from randomly selected features and the output is the average of the all the trees. This reduces the output variance and reduces overfitting. A good value for the number of trees is $\sqrt { p }$ for classification and $\frac { p } { 3 }$ for regression where p is the number of features
Clustering
Expectation-Maximization(EM)
For a mixture of k Gaussians of the form $\mathcal { N } \left( \mu _ { j } , \Sigma _ { j } \right)$
The Expectation step is:
The Maximization step is

K Means Clustering
After randomly initializing the cluster centroids $\mu _ { 1 } , \mu _ { 2 } , \dots , \mu _ { k }$ we repeats the following steps until convergence.

Learning Theory
VC dimension
The Vapnik-Chervonenkis (VC) dimension of a given infinite hypothesis class $\mathcal { H }$ is the size of the largest set that is shattered by $\mathcal { H }$
Given d is the no of features and m is the number of training examples.

Bias Variance Tradeoff
- Bias ― The bias of a model is the difference between the expected prediction and the correct model that we try to predict for given data points.
- Variance ― The variance of a model is the variability of the model prediction for given data points.
- Bias/variance tradeoff ― The simpler the model, the higher the bias, and the more complex the model, the higher the variance.

Cross Validation
Cross-validation ― Cross-validation, also noted CV, is a method that is used to select a model that does not rely too much on the initial training set. The most commonly used method is called k-fold cross-validation and splits the training data into k folds to validate the model on one fold while training the model on the k − 1 other folds, all of this k times. The error is then averaged over the k folds and is named cross-validation error.

Classification metrics
The following metrics are commonly used to assess the performance of classification models where TP is true positive, TN is true negative , FP is false positive and FN is false negative.

ROC ― The receiver operating curve, also noted ROC, is the plot of TPR versus FPR by varying the threshold. AUC ― The area under the receiving operating curve.

