Single Shot Detection
Single Shot MultiBox Detector
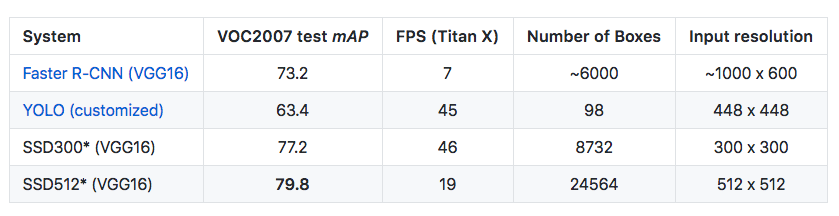
Along with object detection we also want to localize and classify each element within our field of view. The previous architectures such as RCNN and Faster RCNN tried to address this by Bounding boxes and Region proposals where the output is a class label as well as regression outputs for the 4 edges to draw a bounding box. These were slow and real time performance was not possible with them.
SSD paper (Liu et al) addressed this through the following: Single Shot: this means that the tasks of object localization and classification are done in a single forward pass of the network
MultiBox: this is the name of a technique for bounding box regression developed by Szegedy et al.
Detector: The network is an object detector that also classifies those detected objects
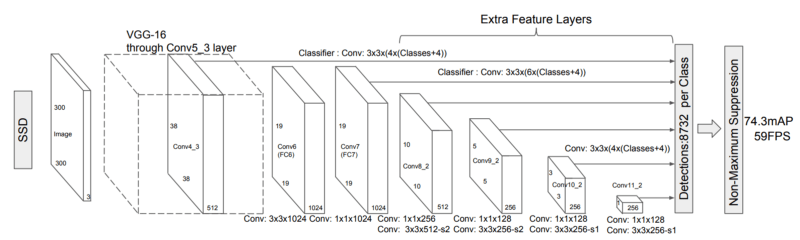
SSD’s architecture builds on the VGG-16 architecture, but discards the fully connected (FC) layers. MultiBox’s loss function also combined two critical components that made their way into SSD:
Confidence Loss: this measures how confident the network is of the objectiveness of the computed bounding box. Categorical cross-entropy is used to compute this loss.
Location Loss: this measures how far away the network’s predicted bounding boxes are from the ground truth ones from the training set. L1Norm is used here.
If IOU is the >0.5
The Final Loss is
In MultiBox, priors are pre-computed, fixed size bounding boxes that closely match the distribution of the original ground truth boxes. In fact those priors are selected in such a way that their Intersection over Union ratio (aka IoU, and sometimes referred to as Jaccard index) is greater than 0.5
Classification:
MultiBox does not perform object classification, whereas SSD does. Therefore, for each predicted bounding box, a set of c class predictions are computed, for every possible class in the dataset.
Non-Maximum Suppression (NMS)
Given the large number of boxes generated during a forward pass of SSD at inference time , it is essential to prune most of the bounding box by applying a technique known as non-maximum suppression: boxes with a confidence loss threshold less than ct (e.g. 0.01) and IoU less than lt (e.g. 0.45) are discarded, and only the top N predictions are kept. This ensures only the most likely predictions are retained by the network, while the more noisier ones are removed.





from __future__ import print_function, division
from builtins import range, input
# Note: you may need to update your version of future
# sudo pip install -U future
import os, sys
from datetime import datetime
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt
from PIL import Image
import imageio
if tf.__version__ < '1.4.0':
raise ImportError(
'Please upgrade your tensorflow installation to v1.4.* or later!'
)
# change this to wherever you cloned the tensorflow models repo
# which I assume you've already downloaded from:
# https://github.com/tensorflow/models
RESEARCH_PATH = '../../tf-models/research'
MODELS_PATH = '../../tf-models/research/object_detection'
sys.path.append(RESEARCH_PATH)
sys.path.append(MODELS_PATH)
# import local modules
import object_detection
from utils import label_map_util
from utils import visualization_utils as vis_util
# I've assumed you already ran the notebook and downloaded the model
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
PATH_TO_CKPT = '%s/%s/frozen_inference_graph.pb' % (MODELS_PATH, MODEL_NAME)
PATH_TO_LABELS = '%s/data/mscoco_label_map.pbtxt' % MODELS_PATH
NUM_CLASSES = 90
# load the model into memory
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# load label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
print("categories:")
print(categories)
# convert image -> numpy array
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# do some object detection
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# Definite input and output Tensors for detection_graph
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# instead of looping through test images, we'll now loop
# through our video!
# get the videos from:
# https://lazyprogrammer.me/cnn_class2_videos.zip
# and put them into the same folder as this file
# open the video
# input_video = 'catdog'
# input_video = 'safari'
input_video = 'traffic'
video_reader = imageio.get_reader('%s.mp4' % input_video)
video_writer = imageio.get_writer('%s_annotated.mp4' % input_video, fps=10)
# loop through and process each frame
t0 = datetime.now()
n_frames = 0
for frame in video_reader:
# rename for convenience
image_np = frame
n_frames += 1
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores, detection_classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
# instead of plotting image, we write the frame to video
video_writer.append_data(image_np)
fps = n_frames / (datetime.now() - t0).total_seconds()
print("Frames processed: %s, Speed: %s fps" % (n_frames, fps))
# clean up
video_writer.close()
def iou(box1, box2):
"""Implement the intersection over union (IoU) between box1 and box2
Arguments:
box1 -- first box, list object with coordinates (x1, y1, x2, y2)
box2 -- second box, list object with coordinates (x1, y1, x2, y2)
"""
# Calculate the (y1, x1, y2, x2) coordinates of the intersection of box1 and box2. Calculate its Area.
### START CODE HERE ### (≈ 5 lines)
xi1 = max(box1[0], box2[0])
yi1 = max(box1[1], box2[1])
xi2 = min(box1[2], box2[2])
yi2 = min(box1[3], box2[3])
inter_area = (xi2 - xi1) * (yi2 - yi1)
### END CODE HERE ###
# Calculate the Union area by using Formula: Union(A,B) = A + B - Inter(A,B)
### START CODE HERE ### (≈ 3 lines)
box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1])
box2_area = (box2[2] - box2[0]) * (box2[3] - box2[1])
union_area = box1_area + box2_area - inter_area
### END CODE HERE ###
# compute the IoU
### START CODE HERE ### (≈ 1 line)
iou = inter_area / union_area
### END CODE HERE ###
return iou
References
- Liu Et AL SSD: Single Shot MultiBox Detector(2015)
- Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recog-nition. In: NIPS. (2015
- Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards real-time object detectionwith region proposal networks. In: NIPS. (2015)
- Szegedy, C., Reed, S., Erhan, D., Anguelov, D.: Scalable, high-quality object detection.arXiv preprint arXiv:1412.1441 v3 (2015)