DCGAN
Generative Adversarial Networks
In Generative Models given training data, we would like to generate new samples from same distribution.

We want to sample from a complex, high-dimensional training distribution. But there is no direct way to do this. So we sample from a simple distribution and learn the transformation to training distribution . GANs(Generative Adversarial Networks): don’t work with any explicit density function. Instead, it takes a game-theoretic approach. It learns to generate from training distribution through 2-player game using a CNN. It has a Generator network which tries to fool the discriminator by generating real-looking images, while the Discriminator network tries to distinguish between real and fake images.

DCGAN is one of the popular and successful network design for GAN. It mainly composes of convolution layers without max pooling or fully connected layers. It uses convolutional stride and transposed convolution for the downsampling and the upsampling. The figure below is the network design for the generator.
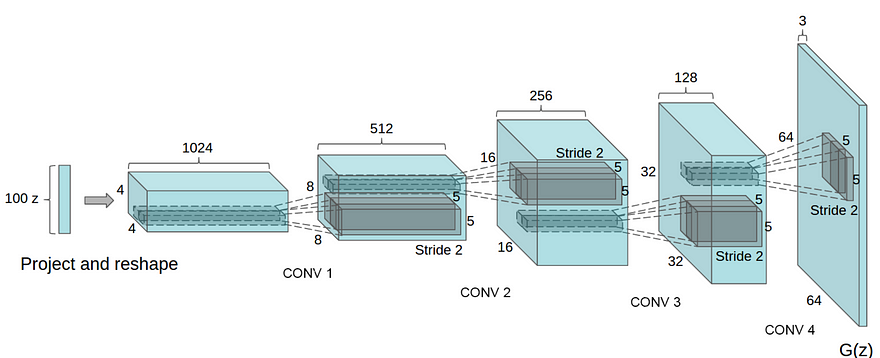
It improves GAN by
- Replace all max pooling with convolutional stride
- Use transposed convolution for upsampling.
- Eliminate fully connected layers.
- Use Batch normalization except the output layer for the generator and the input layer of the discriminator.
- Use ReLU in the generator except for the output which uses tanh.
- Use LeakyReLU in the discriminator.
The cost function of the discriminator and generator is as follows


from __future__ import print_function, division
from builtins import range, input
# Note: you may need to update your version of future
# sudo pip install -U future
import os
import util
import scipy as sp
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from datetime import datetime
# some constants
LEARNING_RATE = 0.0002
BETA1 = 0.5
BATCH_SIZE = 64
EPOCHS = 2
SAVE_SAMPLE_PERIOD = 50
# make dir to save samples
if not os.path.exists('samples'):
os.mkdir('samples')
def lrelu(x, alpha=0.2):
return tf.maximum(alpha*x, x)
class ConvLayer:
def __init__(self, name, mi, mo, apply_batch_norm, filtersz=5, stride=2, f=tf.nn.relu):
# mi = input feature map size
# mo = output feature map size
# self.W = tf.Variable(0.02*tf.random_normal(shape=(filtersz, filtersz, mi, mo)))
# self.b = tf.Variable(np.zeros(mo, dtype=np.float32))
self.W = tf.get_variable(
"W_%s" % name,
shape=(filtersz, filtersz, mi, mo),
# initializer=tf.contrib.layers.xavier_initializer(),
initializer=tf.truncated_normal_initializer(stddev=0.02),
)
self.b = tf.get_variable(
"b_%s" % name,
shape=(mo,),
initializer=tf.zeros_initializer(),
)
self.name = name
self.f = f
self.stride = stride
self.apply_batch_norm = apply_batch_norm
self.params = [self.W, self.b]
def forward(self, X, reuse, is_training):
# print("**************** reuse:", reuse)
conv_out = tf.nn.conv2d(
X,
self.W,
strides=[1, self.stride, self.stride, 1],
padding='SAME'
)
conv_out = tf.nn.bias_add(conv_out, self.b)
# apply batch normalization
if self.apply_batch_norm:
conv_out = tf.contrib.layers.batch_norm(
conv_out,
decay=0.9,
updates_collections=None,
epsilon=1e-5,
scale=True,
is_training=is_training,
reuse=reuse,
scope=self.name,
)
return self.f(conv_out)
class FractionallyStridedConvLayer:
def __init__(self, name, mi, mo, output_shape, apply_batch_norm, filtersz=5, stride=2, f=tf.nn.relu):
# mi = input feature map size
# mo = output feature map size
# NOTE!!! shape is specified in the OPPOSITE way from regular conv
# self.W = tf.Variable(0.02*tf.random_normal(shape=(filtersz, filtersz, mo, mi)))
# self.b = tf.Variable(np.zeros(mo, dtype=np.float32))
self.W = tf.get_variable(
"W_%s" % name,
shape=(filtersz, filtersz, mo, mi),
# initializer=tf.contrib.layers.xavier_initializer(),
initializer=tf.random_normal_initializer(stddev=0.02),
)
self.b = tf.get_variable(
"b_%s" % name,
shape=(mo,),
initializer=tf.zeros_initializer(),
)
self.f = f
self.stride = stride
self.name = name
self.output_shape = output_shape
self.apply_batch_norm = apply_batch_norm
self.params = [self.W, self.b]
def forward(self, X, reuse, is_training):
conv_out = tf.nn.conv2d_transpose(
value=X,
filter=self.W,
output_shape=self.output_shape,
strides=[1, self.stride, self.stride, 1],
)
conv_out = tf.nn.bias_add(conv_out, self.b)
# apply batch normalization
if self.apply_batch_norm:
conv_out = tf.contrib.layers.batch_norm(
conv_out,
decay=0.9,
updates_collections=None,
epsilon=1e-5,
scale=True,
is_training=is_training,
reuse=reuse,
scope=self.name,
)
return self.f(conv_out)
class DenseLayer(object):
def __init__(self, name, M1, M2, apply_batch_norm, f=tf.nn.relu):
self.W = tf.get_variable(
"W_%s" % name,
shape=(M1, M2),
initializer=tf.random_normal_initializer(stddev=0.02),
)
self.b = tf.get_variable(
"b_%s" % name,
shape=(M2,),
initializer=tf.zeros_initializer(),
)
self.f = f
self.name = name
self.apply_batch_norm = apply_batch_norm
self.params = [self.W, self.b]
def forward(self, X, reuse, is_training):
a = tf.matmul(X, self.W) + self.b
# apply batch normalization
if self.apply_batch_norm:
a = tf.contrib.layers.batch_norm(
a,
decay=0.9,
updates_collections=None,
epsilon=1e-5,
scale=True,
is_training=is_training,
reuse=reuse,
scope=self.name,
)
return self.f(a)
class DCGAN:
def __init__(self, img_length, num_colors, d_sizes, g_sizes):
# save for later
self.img_length = img_length
self.num_colors = num_colors
self.latent_dims = g_sizes['z']
# define the input data
self.X = tf.placeholder(
tf.float32,
shape=(None, img_length, img_length, num_colors),
name='X'
)
self.Z = tf.placeholder(
tf.float32,
shape=(None, self.latent_dims),
name='Z'
)
# note: by making batch_sz a placeholder, we can specify a variable
# number of samples in the FS-conv operation where we are required
# to pass in output_shape
# we need only pass in the batch size via feed_dict
self.batch_sz = tf.placeholder(tf.int32, shape=(), name='batch_sz')
# build the discriminator
logits = self.build_discriminator(self.X, d_sizes)
# build generator
self.sample_images = self.build_generator(self.Z, g_sizes)
# get sample logits
with tf.variable_scope("discriminator") as scope:
scope.reuse_variables()
sample_logits = self.d_forward(self.sample_images, True)
# get sample images for test time (batch norm is different)
with tf.variable_scope("generator") as scope:
scope.reuse_variables()
self.sample_images_test = self.g_forward(
self.Z, reuse=True, is_training=False
)
# build costs
self.d_cost_real = tf.nn.sigmoid_cross_entropy_with_logits(
logits=logits,
labels=tf.ones_like(logits)
)
self.d_cost_fake = tf.nn.sigmoid_cross_entropy_with_logits(
logits=sample_logits,
labels=tf.zeros_like(sample_logits)
)
self.d_cost = tf.reduce_mean(self.d_cost_real) + tf.reduce_mean(self.d_cost_fake)
self.g_cost = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(
logits=sample_logits,
labels=tf.ones_like(sample_logits)
)
)
real_predictions = tf.cast(logits > 0, tf.float32)
fake_predictions = tf.cast(sample_logits < 0, tf.float32)
num_predictions = 2.0*BATCH_SIZE
num_correct = tf.reduce_sum(real_predictions) + tf.reduce_sum(fake_predictions)
self.d_accuracy = num_correct / num_predictions
# optimizers
self.d_params = [t for t in tf.trainable_variables() if t.name.startswith('d')]
self.g_params = [t for t in tf.trainable_variables() if t.name.startswith('g')]
self.d_train_op = tf.train.AdamOptimizer(
LEARNING_RATE, beta1=BETA1
).minimize(
self.d_cost, var_list=self.d_params
)
self.g_train_op = tf.train.AdamOptimizer(
LEARNING_RATE, beta1=BETA1
).minimize(
self.g_cost, var_list=self.g_params
)
# show_all_variables()
# exit()
# set up session and variables for later
self.init_op = tf.global_variables_initializer()
self.sess = tf.InteractiveSession()
self.sess.run(self.init_op)
def build_discriminator(self, X, d_sizes):
with tf.variable_scope("discriminator") as scope:
# build conv layers
self.d_convlayers = []
mi = self.num_colors
dim = self.img_length
count = 0
for mo, filtersz, stride, apply_batch_norm in d_sizes['conv_layers']:
# make up a name - used for get_variable
name = "convlayer_%s" % count
count += 1
layer = ConvLayer(name, mi, mo, apply_batch_norm, filtersz, stride, lrelu)
self.d_convlayers.append(layer)
mi = mo
print("dim:", dim)
dim = int(np.ceil(float(dim) / stride))
mi = mi * dim * dim
# build dense layers
self.d_denselayers = []
for mo, apply_batch_norm in d_sizes['dense_layers']:
name = "denselayer_%s" % count
count += 1
layer = DenseLayer(name, mi, mo, apply_batch_norm, lrelu)
mi = mo
self.d_denselayers.append(layer)
# final logistic layer
name = "denselayer_%s" % count
self.d_finallayer = DenseLayer(name, mi, 1, False, lambda x: x)
# get the logits
logits = self.d_forward(X)
# build the cost later
return logits
def d_forward(self, X, reuse=None, is_training=True):
# encapsulate this because we use it twice
output = X
for layer in self.d_convlayers:
output = layer.forward(output, reuse, is_training)
output = tf.contrib.layers.flatten(output)
for layer in self.d_denselayers:
output = layer.forward(output, reuse, is_training)
logits = self.d_finallayer.forward(output, reuse, is_training)
return logits
def build_generator(self, Z, g_sizes):
with tf.variable_scope("generator") as scope:
# determine the size of the data at each step
dims = [self.img_length]
dim = self.img_length
for _, _, stride, _ in reversed(g_sizes['conv_layers']):
dim = int(np.ceil(float(dim) / stride))
dims.append(dim)
# note: dims is actually backwards
# the first layer of the generator is actually last
# so let's reverse it
dims = list(reversed(dims))
print("dims:", dims)
self.g_dims = dims
# dense layers
mi = self.latent_dims
self.g_denselayers = []
count = 0
for mo, apply_batch_norm in g_sizes['dense_layers']:
name = "g_denselayer_%s" % count
count += 1
layer = DenseLayer(name, mi, mo, apply_batch_norm)
self.g_denselayers.append(layer)
mi = mo
# final dense layer
mo = g_sizes['projection'] * dims[0] * dims[0]
name = "g_denselayer_%s" % count
layer = DenseLayer(name, mi, mo, not g_sizes['bn_after_project'])
self.g_denselayers.append(layer)
# fs-conv layers
mi = g_sizes['projection']
self.g_convlayers = []
# output may use tanh or sigmoid
num_relus = len(g_sizes['conv_layers']) - 1
activation_functions = [tf.nn.relu]*num_relus + [g_sizes['output_activation']]
for i in range(len(g_sizes['conv_layers'])):
name = "fs_convlayer_%s" % i
mo, filtersz, stride, apply_batch_norm = g_sizes['conv_layers'][i]
f = activation_functions[i]
output_shape = [self.batch_sz, dims[i+1], dims[i+1], mo]
print("mi:", mi, "mo:", mo, "outp shape:", output_shape)
layer = FractionallyStridedConvLayer(
name, mi, mo, output_shape, apply_batch_norm, filtersz, stride, f
)
self.g_convlayers.append(layer)
mi = mo
# get the output
self.g_sizes = g_sizes
return self.g_forward(Z)
def g_forward(self, Z, reuse=None, is_training=True):
# dense layers
output = Z
for layer in self.g_denselayers:
output = layer.forward(output, reuse, is_training)
# project and reshape
output = tf.reshape(
output,
[-1, self.g_dims[0], self.g_dims[0], self.g_sizes['projection']],
)
# apply batch norm
if self.g_sizes['bn_after_project']:
output = tf.contrib.layers.batch_norm(
output,
decay=0.9,
updates_collections=None,
epsilon=1e-5,
scale=True,
is_training=is_training,
reuse=reuse,
scope='bn_after_project'
)
# pass through fs-conv layers
for layer in self.g_convlayers:
output = layer.forward(output, reuse, is_training)
return output
def fit(self, X):
d_costs = []
g_costs = []
N = len(X)
n_batches = N // BATCH_SIZE
total_iters = 0
for i in range(EPOCHS):
print("epoch:", i)
np.random.shuffle(X)
for j in range(n_batches):
t0 = datetime.now()
if type(X[0]) is str:
# is celeb dataset
batch = util.files2images(
X[j*BATCH_SIZE:(j+1)*BATCH_SIZE]
)
else:
# is mnist dataset
batch = X[j*BATCH_SIZE:(j+1)*BATCH_SIZE]
Z = np.random.uniform(-1, 1, size=(BATCH_SIZE, self.latent_dims))
# train the discriminator
_, d_cost, d_acc = self.sess.run(
(self.d_train_op, self.d_cost, self.d_accuracy),
feed_dict={self.X: batch, self.Z: Z, self.batch_sz: BATCH_SIZE},
)
d_costs.append(d_cost)
# train the generator
_, g_cost1 = self.sess.run(
(self.g_train_op, self.g_cost),
feed_dict={self.Z: Z, self.batch_sz: BATCH_SIZE},
)
# g_costs.append(g_cost1)
_, g_cost2 = self.sess.run(
(self.g_train_op, self.g_cost),
feed_dict={self.Z: Z, self.batch_sz: BATCH_SIZE},
)
g_costs.append((g_cost1 + g_cost2)/2) # just use the avg
print(" batch: %d/%d - dt: %s - d_acc: %.2f" % (j+1, n_batches, datetime.now() - t0, d_acc))
# save samples periodically
total_iters += 1
if total_iters % SAVE_SAMPLE_PERIOD == 0:
print("saving a sample...")
samples = self.sample(64) # shape is (64, D, D, color)
# for convenience
d = self.img_length
if samples.shape[-1] == 1:
# if color == 1, we want a 2-D image (N x N)
samples = samples.reshape(64, d, d)
flat_image = np.empty((8*d, 8*d))
k = 0
for i in range(8):
for j in range(8):
flat_image[i*d:(i+1)*d, j*d:(j+1)*d] = samples[k].reshape(d, d)
k += 1
# plt.imshow(flat_image, cmap='gray')
else:
# if color == 3, we want a 3-D image (N x N x 3)
flat_image = np.empty((8*d, 8*d, 3))
k = 0
for i in range(8):
for j in range(8):
flat_image[i*d:(i+1)*d, j*d:(j+1)*d] = samples[k]
k += 1
# plt.imshow(flat_image)
# plt.savefig('samples/samples_at_iter_%d.png' % total_iters)
sp.misc.imsave(
'samples/samples_at_iter_%d.png' % total_iters,
flat_image,
)
# save a plot of the costs
plt.clf()
plt.plot(d_costs, label='discriminator cost')
plt.plot(g_costs, label='generator cost')
plt.legend()
plt.savefig('cost_vs_iteration.png')
def sample(self, n):
Z = np.random.uniform(-1, 1, size=(n, self.latent_dims))
samples = self.sess.run(self.sample_images_test, feed_dict={self.Z: Z, self.batch_sz: n})
return samples
def celeb():
X = util.get_celeb()
# just loads a list of filenames, we will load them in dynamically
# because there are many
dim = 64
colors = 3
# for celeb
d_sizes = {
'conv_layers': [
(64, 5, 2, False),
(128, 5, 2, True),
(256, 5, 2, True),
(512, 5, 2, True)
],
'dense_layers': [],
}
g_sizes = {
'z': 100,
'projection': 512,
'bn_after_project': True,
'conv_layers': [
(256, 5, 2, True),
(128, 5, 2, True),
(64, 5, 2, True),
(colors, 5, 2, False)
],
'dense_layers': [],
'output_activation': tf.tanh,
}
# setup gan
# note: assume square images, so only need 1 dim
gan = DCGAN(dim, colors, d_sizes, g_sizes)
gan.fit(X)
def mnist():
X, Y = util.get_mnist()
X = X.reshape(len(X), 28, 28, 1)
dim = X.shape[1]
colors = X.shape[-1]
# for mnist
d_sizes = {
'conv_layers': [(2, 5, 2, False), (64, 5, 2, True)],
'dense_layers': [(1024, True)],
}
g_sizes = {
'z': 100,
'projection': 128,
'bn_after_project': False,
'conv_layers': [(128, 5, 2, True), (colors, 5, 2, False)],
'dense_layers': [(1024, True)],
'output_activation': tf.sigmoid,
}
# setup gan
# note: assume square images, so only need 1 dim
gan = DCGAN(dim, colors, d_sizes, g_sizes)
gan.fit(X)
# samples = gan.sample(1) # just making sure it works
# since training will take a considerable
# amount of time, let's just save some
# samples to disk rather than plotting now
if __name__ == '__main__':
# celeb()
mnist()